Assignment
- Implement a kubernetes solution to contanerize the project that will be shared along with this problem.
- Implement a very simple API server with the following routes that can interact with kubernetes.
POST /jobs(Create a new job that runs on a kubernetes cluster)GET /jobs/stats(Returns aggregate job stats. Succeeded vs failed and no of retries)POST /jobs/schedule(Schedule a job using cron syntax)
- The project is wrritten in Rust and we need to containerize the project to serve following
- Each job should spawn a docker container and run Rust function from binary script.
- If the job fails, retry 2 times with a small time delay ideally.
Abstract
- This post demonstrates a proof-of-concept implementation that uses Kubernetes to execute code in response to an event here is API request. The workflow is powered by Keda (Kubernetes Event-driven Autoscaling) which scales out the kubernetes pods bases on incoming events such as SQS messages. After keda scaleout pods which are in pending state, Karpenter (Just-in-time Nodes for Any Kubernetes Cluster) bases on provisioners to decide scaleout more nodes
- Keda and Karpenter AddOn with Amazon Elastic Kubernetes Service (Amazon EKS), making it easy to build event-driven workflows that orchestrate jobs running on Kubernetes with AWS services, such as AWS Lambda, HTTP API Gateway, DynamoDB and Amazon Simple Queue Service (Amazon SQS), with minimal code.
- All AWS resources as well as kubernetes manifest and kubernetes AddOns are managed and installed using CDK (AWS Cloud Development Kit) and CDK8S (Cloud Development Kit for Kubernetes)
TL;DR
Table Of Contents
Open Table Of Contents
🚀 Solution overview
-
Bootstrapping clusters with EKS Blueprints, the cluster includes AddOns such as Keda, Karpenter and others
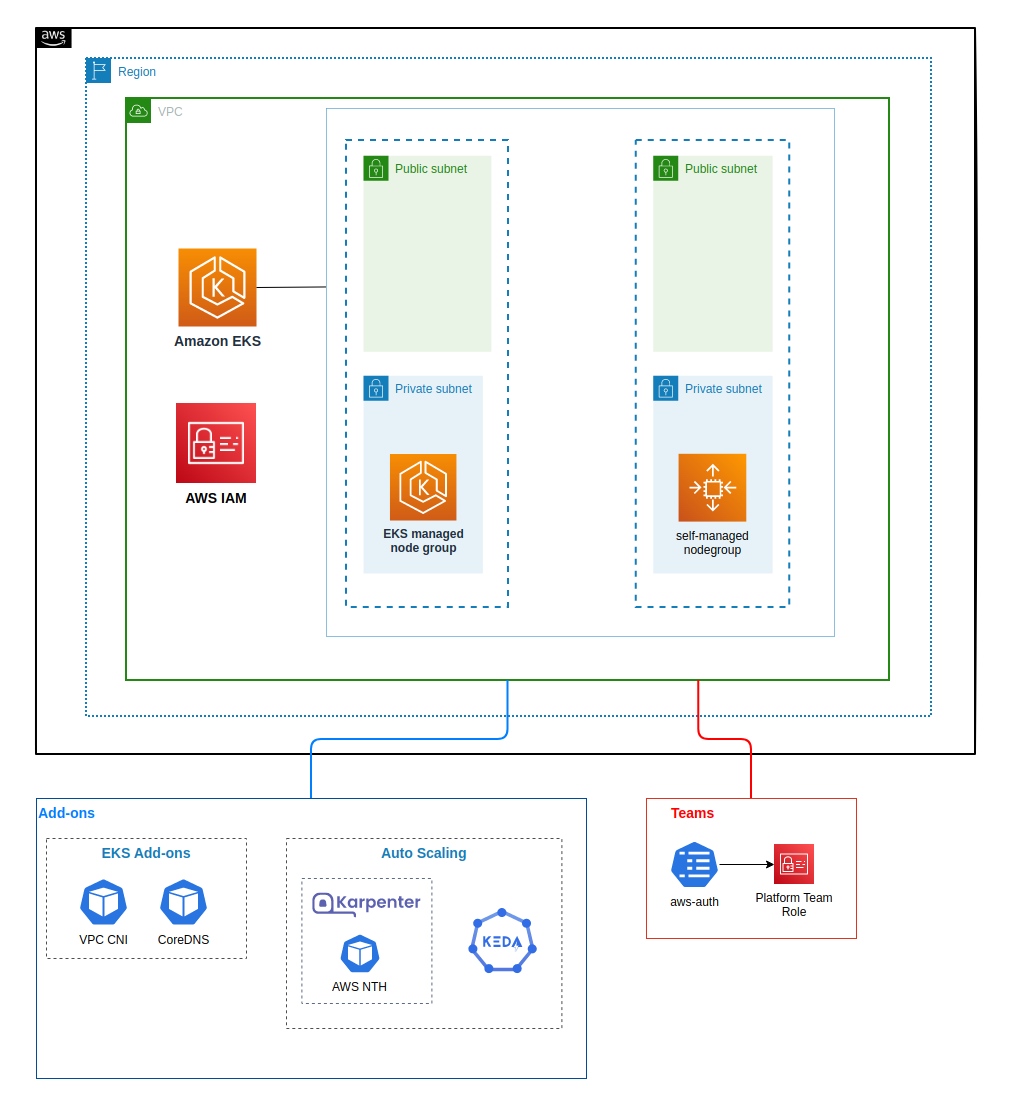
-
The API server is hosted by HTTP API gateway with lambda integration
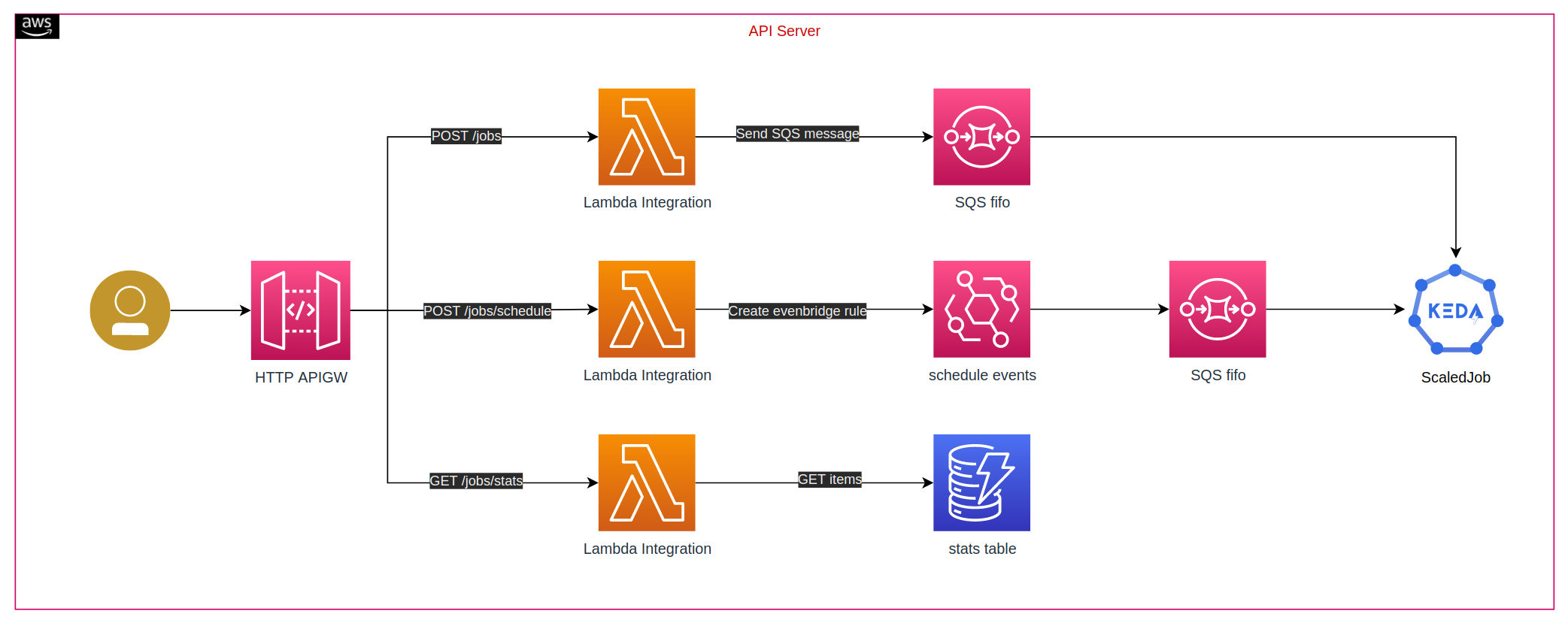
POST /jobs- Lambda function send SQS message, keda scaledJob listens to the SQS queue and then scaleout job to serve the request, karpenter catches pod pending event to provision new nodeGET /jobs/stats- Lambda function query dynamoDB table to get job aggregation stats and return the result for job succeed, failed and number of retries.POST /jobs/schedule- Lambda function create eventbridgeSchedulerule with Cron expression from the input of cron syntax. Eventbridge rule will send SQS message for triggering keda scaledjob
🚀 Containerize the project
-
⚡ $ tree data_processor/ data_processor/ ├── Cargo.toml ├── Dockerfile ├── README.md └── src └── main.rs 1 directory, 5 files -
In the
main.rsthere are three main tasks in this project- Processing job
- Consume and delete SQS message
- Write succeed, fail and retry state to dynamodb
-
We leverage multi-stage builds in Dockerfile to optimize the image size and running process as non-root user for security.
- First stage compile Rust source code to binary
data-processor-sample - Last stage copy binary and define the
ENTRYPOINT ["/data-processor-sample"]underUSER rustso whenever the container starts, it automatically trigger processing jobs.
- First stage compile Rust source code to binary
-
Build, tag and push image
⚡ $ cd data_processor/ ⚡ $ docker build -t dozer/process-job . Sending build context to Docker daemon 52.74kB Successfully built 8b8178a8f41f Successfully tagged dozer/process-job:latest ⚡ $ docker tag dozer/process-job:latest 123456789012.dkr.ecr.ap-southeast-1.amazonaws.com/dozer/process-job:latest ⚡ $ docker push 123456789012.dkr.ecr.ap-southeast-1.amazonaws.com/dozer/process-job:latest
🚀 Create K8S Charts for keda scaledJob, provisioner and serviceAccount
-
If you know helm chart or kustomize to provision managed kubernetes manifest at scale, CDK8S not only provide those benefits but also more
- cdk8s is an open-source software development framework for defining Kubernetes applications and reusable abstractions using familiar programming languages here I use TypeScript
- We can combine CDK and CDK8S to single project and apply CDK8S Charts inside the EKS cluster stacks and then just run deploy
⚡ $ tree aws-k8s-iac/src/cdk8s/ aws-k8s-iac/src/cdk8s/ ├── imports │ ├── k8s.ts │ ├── karpenter.sh.ts │ └── keda.sh.ts ├── karpenter-provisioner │ ├── dozer-job-provisoner.ts │ └── provisioner-constants.ts ├── keda │ └── dozer-job.ts ├── main.ts └── serviceAccount └── processor-job-sa.ts 4 directories, 8 files -
For designing event-driven with autoscaling and cost optimization, we use Keda scaledJob with SQS triggers. In the scaledJob, we define following specs
-
jobTargetRefwhich contains the k8s job spec -
pollingIntervalwhich is the period of polling to the SQS queue -
minReplicaCountis set to 0 means no SQS message no job -
maxReplicaCountto control the max number of scaled jobs so first come first serve -
triggersdefines SQS target to poll for messages -
serviceAccountNameIAM role for accessing AWS resources -
Source code: dozer-job.ts
-
Check scaledobject created
~ $ k get scaledjob NAME MAX TRIGGERS AUTHENTICATION READY ACTIVE AGE dozer-job 4 aws-sqs-queue True False 24h
-
-
For autoscaling, we use Karpenter with proper provioner spec. The provisoner includes following major spec
-
instanceProfileAWS instance profile with enough IAM permissions for nodes to join EKS cluster -
amiFamilyUseBottlerocketfor optimize AMI and security -
subnetSelectorProvide tags of EKS private subnets -
securityGroupSelectorProvide tags of EKS security group for pods communication -
ttlSecondsAfterEmptydelete empty/unnecessary instances -
requirements- Use spot instances with proper instance type
- Taint the EKS nodes with proper key-values for the project
-
Source code: dozer-job-provisoner.ts
-
Check provisioner created
~ $ k get provisioner NAME AGE dozer-job 23h
-
-
ServiceAccount which associates with IAM role for serviceAccount, it’s best practice to provide service permissions to access AWS resources, processor-job-sa.ts
~ $ k get sa NAME SECRETS AGE default 1 4d16h dozer-job 1 23h
🚀 Create EKS Cluster and other resourses using CDK EKS blueprints
-
We use CDK typescript to provide Infrastructure as code
⚡ $ tree aws-k8s-iac/src/ aws-k8s-iac/src/ ├── apigw-lambda-sqs.ts ├── ddb.ts ├── ecr.ts ├── eks-blueprints │ ├── builder.ts │ ├── eks-blueprint.ts │ └── platform-user.ts ├── irsa.ts ├── lambda-handler │ └── index.py ├── main.ts └── shared ├── configs.ts ├── constants.ts ├── environment.ts └── tagging.ts 8 directories, 21 files -
Overview of CDK stacks
⚡ $ cdk ls DevEksCluster DevEksCluster/sin-DozerDDB DevEksCluster/sin-DozerECR DevEksCluster/sin-DozerProcessData DevEksCluster/sin-d1-dev-eks-blueprint DevEksCluster/sin-DozerIRSA -
After creating
.envwithCDK_DEFAULT_ACCOUNTandCDK_DEFAULT_REGIONwe can runcdk deploy --allto create resources. Check cloudformation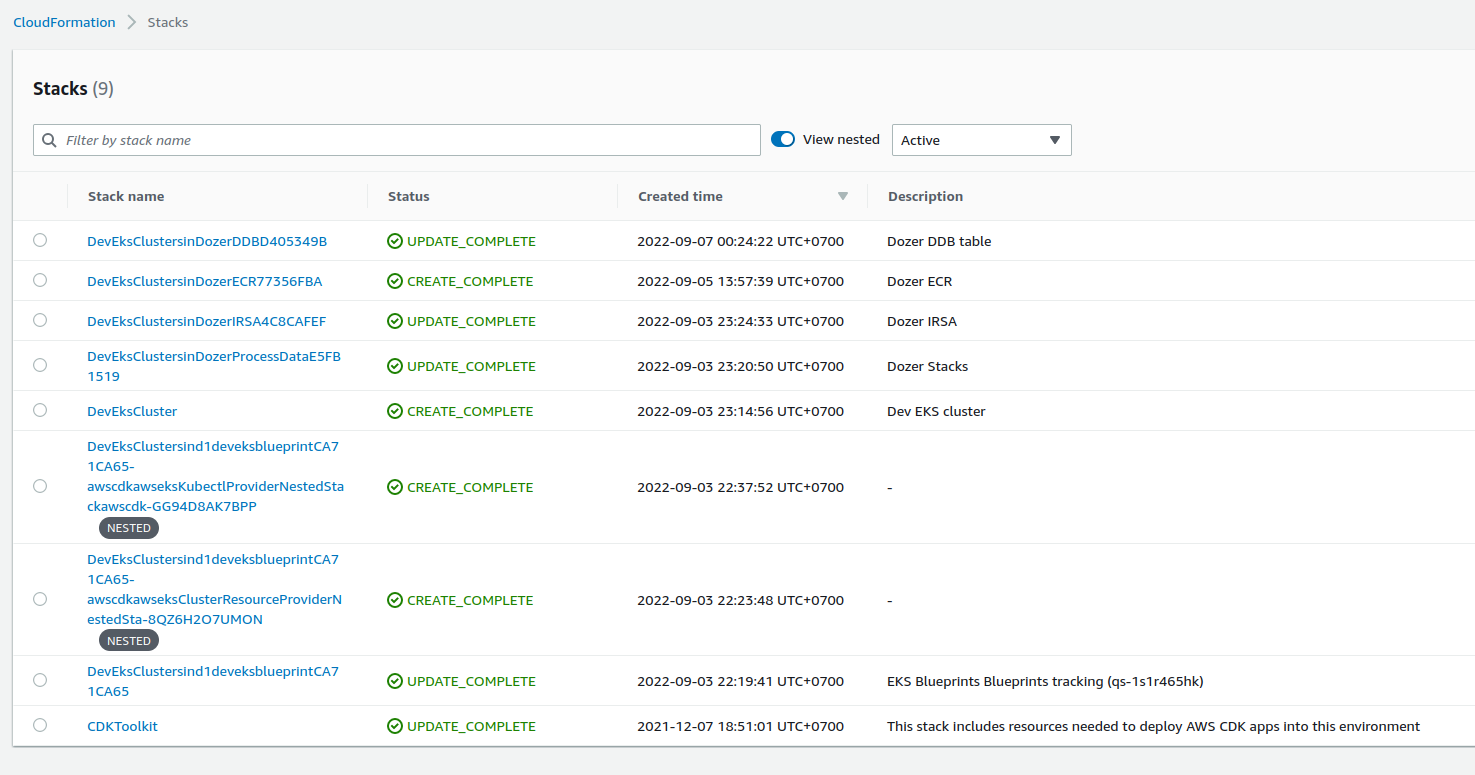
-
Overview of all components

🚀 Test API
-
Overview of HTTP API Gateway
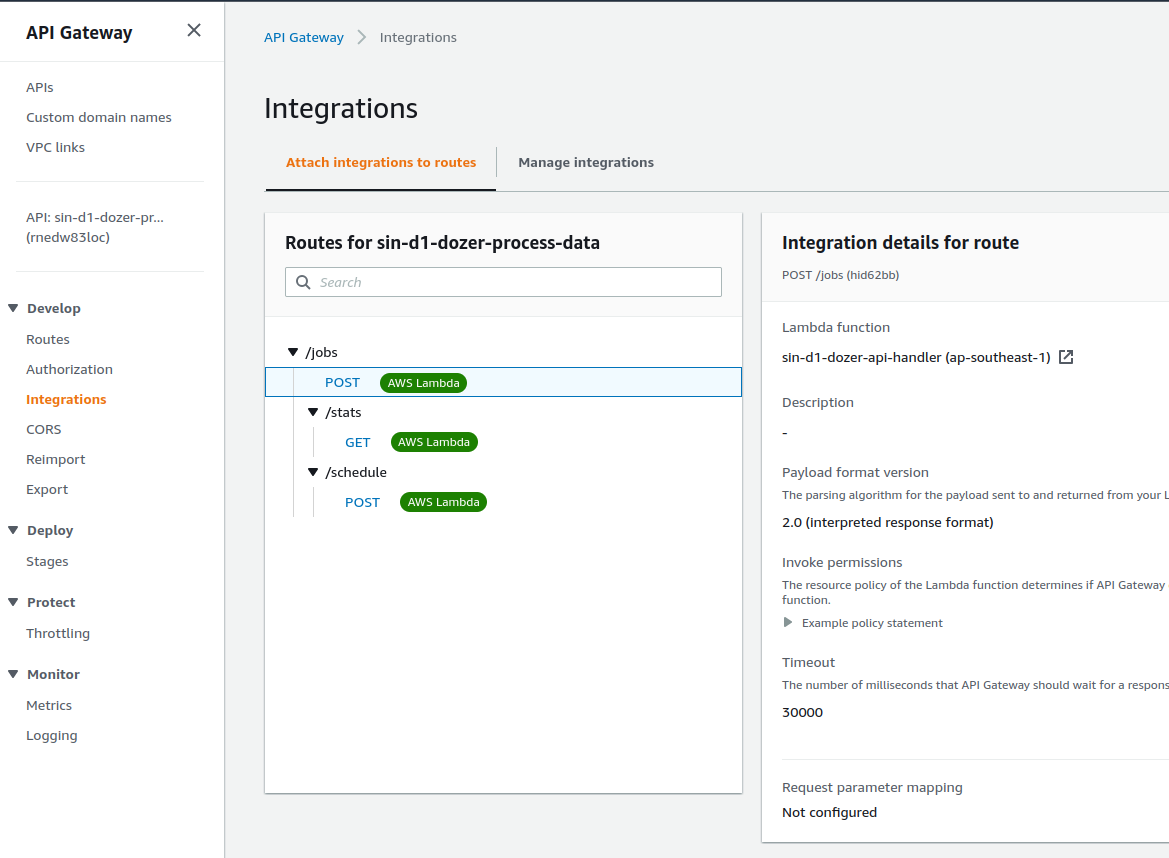
-
Create a new job that runs on a kubernetes cluster
- Send
POSTrequest
curl -X POST https://ww47is207g.execute-api.ap-southeast-1.amazonaws.com/jobs 200- Keda scales job and Karpenter scale node
- New node joined
~ $ k get node NAME STATUS ROLES AGE VERSION ip-10-0-103-57.ap-southeast-1.compute.internal Ready <none> 52s v1.21.13 ip-10-0-118-81.ap-southeast-1.compute.internal Ready <none> 122m v1.21.13 ip-10-0-151-134.ap-southeast-1.compute.internal Ready <none> 122m v1.21.13 - Job created
~ $ k get pod --watch NAME READY STATUS RESTARTS AGE dozer-job-kl8kd-dmq85 0/1 Pending 0 22s dozer-job-kl8kd-dmq85 0/1 ContainerCreating 0 23s dozer-job-kl8kd-dmq85 1/1 Running 0 68s dozer-job-kl8kd-dmq85 0/1 Completed 0 74s dozer-job-9qxrm-s8p6p 0/1 Pending 0 0s dozer-job-9qxrm-s8p6p 0/1 ContainerCreating 0 0s dozer-job-9qxrm-s8p6p 1/1 Running 0 2s dozer-job-9qxrm-s8p6p 0/1 Error 0 7s dozer-job-9qxrm-9m27d 0/1 Pending 0 0s dozer-job-9qxrm-9m27d 0/1 ContainerCreating 0 0s dozer-job-9qxrm-9m27d 1/1 Running 0 1s dozer-job-9qxrm-9m27d 0/1 Error 0 2s dozer-job-9qxrm-5d4vc 0/1 Pending 0 0s dozer-job-9qxrm-5d4vc 0/1 ContainerCreating 0 0s dozer-job-9qxrm-5d4vc 1/1 Running 0 2s dozer-job-9qxrm-5d4vc 0/1 Error 0 3s
- New node joined
- Send
-
Get job aggregation stats
-
Send
GETrequest~ $ curl -X GET https://ww47is207g.execute-api.ap-southeast-1.amazonaws.com/jobs/stats {"succeedJob": 1, "jobRetry": 2, "failedJob": 3} -
Double check dynamoDB table
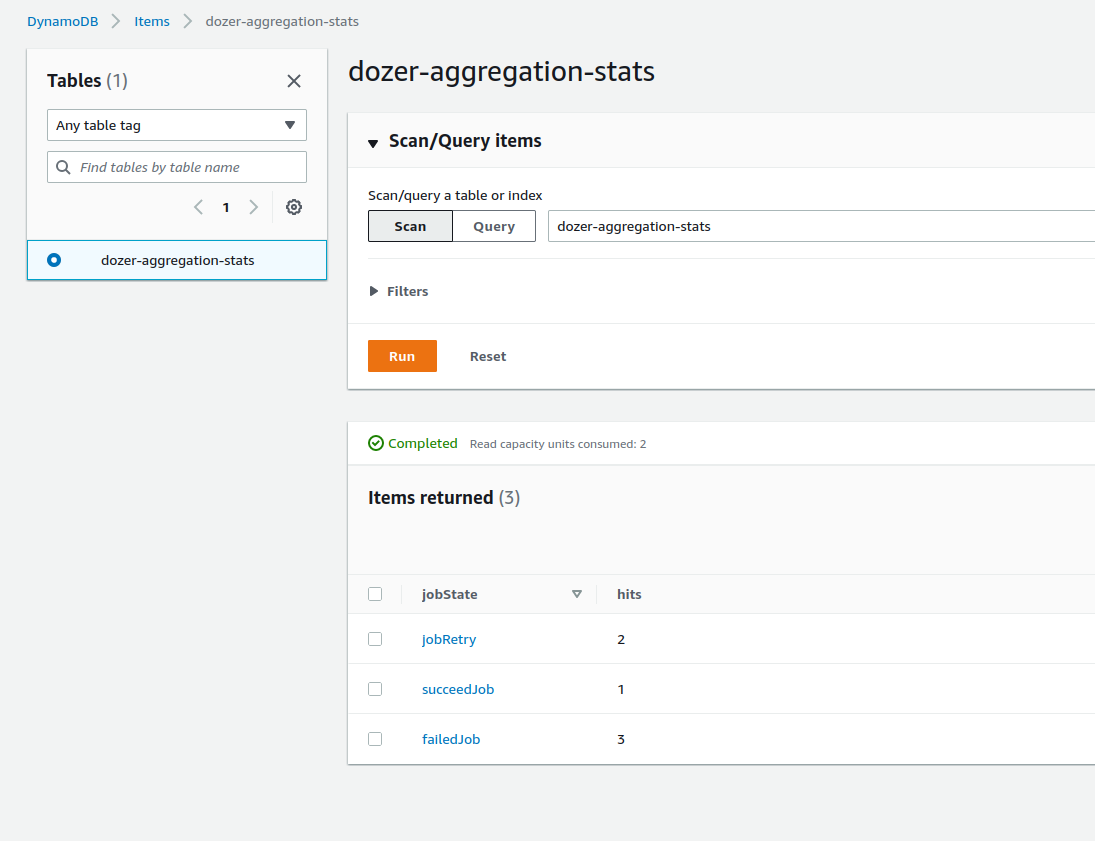
-
-
Schedule a job using cron syntax
-
Send
POSTrequestcurl -X POST https://ww47is207g.execute-api.ap-southeast-1.amazonaws.com/jobs/schedule --data '{"cron": "* * * * *"}' --header "Content-Type: application/json" 200 ~ $ curl -X POST https://ww47is207g.execute-api.ap-southeast-1.amazonaws.com/jobs/schedule --data '{"cron": "0 7 * * MON"}' --header "Content-Type: application/json" 200 -
Check eventbridge schedules
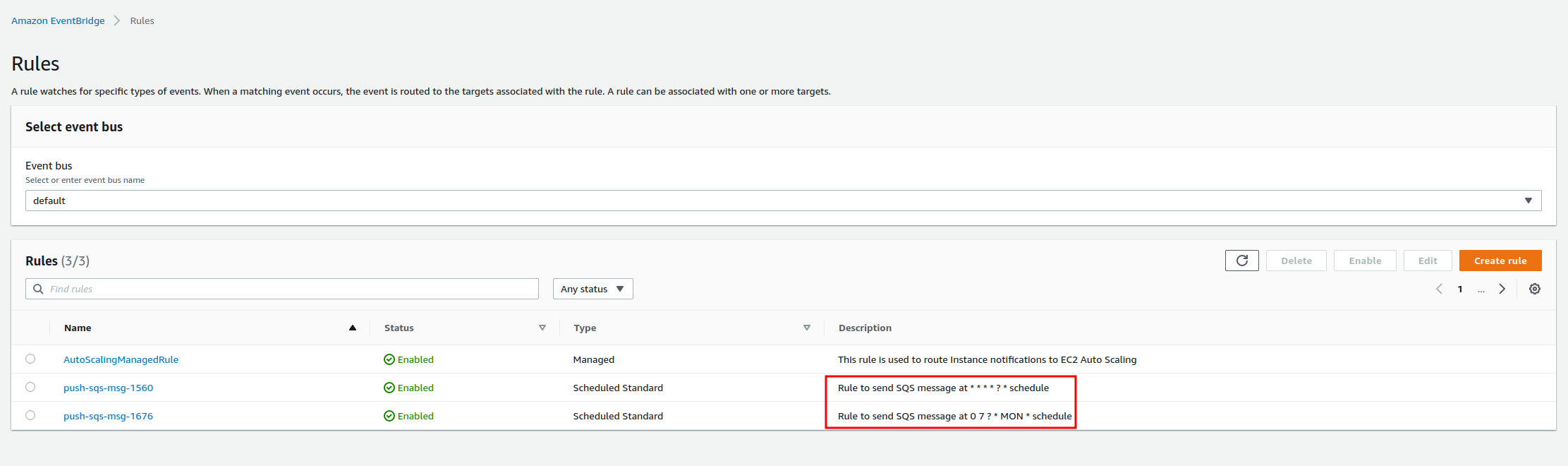
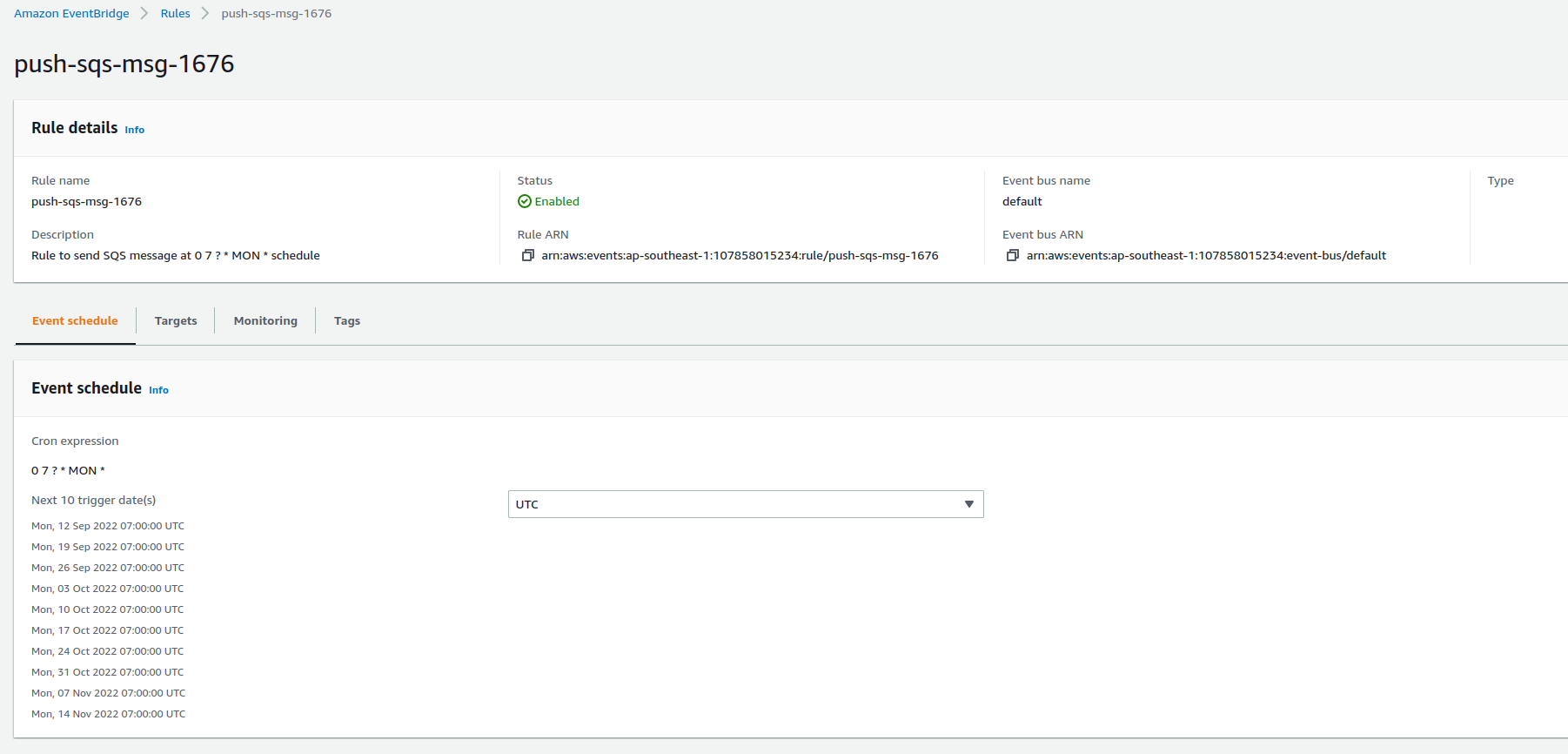
-
Let the schedule of triggering per minute run for a while and then check job stats again
~ $ curl -X GET https://ww47is207g.execute-api.ap-southeast-1.amazonaws.com/jobs/stats {"succeedJob": 13, "jobRetry": 12, "failedJob": 15}
-
🚀 Conclusion
- This post showed how to run event-driven workflows using API request at scale on Amazon EKS, HTTP APIGW and AWS Lambda. We provided you with AWS CDK code as well as CDK8S code to create the cloud infrastructure, Kubernetes resources, and the application within the same codebase.
- In real project, we can do some improvements
POSTjob request will base on the request ID to separate which job ID, which user triggered- Security the API endpoint
- Implement CDK pipeline for the codebase